1500 words today. This is going to be a long, long post about an unusual topic as I need to record my thoughts on this.
Before we get into the topic of the night, I recorded The Writer’s Journey as well as uploaded all seven weeks of Writing Tip of the Day that I recorded yesterday. That took a good deal, but now the show is locked and loaded through the end of February, with more episodes recorded and ready to upload once my monthly storage counter resets on Monday.
A NEW MINI-PROJECT I’M WORKING ON: EDITING ANALYTICS
As I’m waiting for my fact checkers to get my novel back, I have a lot of time on my hands. Some of you know that I’ve been itching to create an “editing rules engine.” My thoughts may be scattered tonight, but that’s because I’m trying to figure out the best way to explain this, so I appreciate your patience and your feedback.
The gist of the “editing rules engine” is that I create a database of errors that my editor(s) made in the past. The errors in the database are errors that can be addressed PROGRAMMATICALLY, which means that if I could have gone back in time, I could have caught the error either using:
- Microsoft Word Macros (they can help you catch simple errors that the spelling and grammar checker, can’t. I don’t know anyone who uses them this way, but I do.)
- Natural Language Processing Artificial Intelligence (this is more complicated and out of scope right now, as I’ll need a developer to help me. But I ran a pilot with one of my audience members last summer and we were able to build a simple prototype that caught spelling/grammar errors that Word/Grammarly/ProWritingAid DIDN’T catch. It was kind of a big deal).
Anyway, for every novel I write, my long-term goal is to “feed” the editor’s edits into my editing engine, so that it gets smarter over time and helps me catch more “Michael La Ronn” errors—errors that I myself am prone to making, not a general audience of general users who may not even be writers—that’s what you get with Grammarly, for example.
In short, I’m building a tool that will help me become a better version of myself.
WHAT IS EDITING ANALYTICS?
The use of analytics to improve your editing is what I call “editing analytics.” As far as I know, I’m the only one in our community who’s ever talked about this, so I’m going to claim that term. LOL
Editing analytics is about using analytics from YOUR work (and YOUR work only) to gain insights into how to become a better writer. It’s about discovering errors that you shouldn’t be making so you can correct them in the future. It means looking back on the editing data a few of your novels so that you can be more proactive.
(Developmental editing is out of scope here. We’re talking strictly about copyediting and proofreading.)
We talk all the time about “writing analytics”, don’t we? Examples of “writing analytics” include how many words you wrote over a period of time, improving your word counts, addressing your productivity through addressing your habits, etc. I do this all the time, and have done it for the last month with my exercise bike challenge.
Things like word count, streaks, average session word counts, etc. That’s writing analytics.
But when you write, you also need to find a way to hold yourself accountable to the quality of your work. That’s only way you’ll improve. In other words, improving your writing speed is only half of the equation. You also need to think about improving your writing accuracy.
Your editor isn’t the silver bullet. Editors miss a lot of stuff. Trust me on this.
I’ve been playing around with the idea of finding ways to catch more errors so that my editor can spend time looking for errors that only they can catch.
For example, there’s just no excuse for an editor to correct the colons in my work. If I don’t use that correctly, that’s my problem, not theirs. Same with lay vs. lie.
ALL EDITS FALL INTO TWO CATEGORIES
I’ve talked about them over the last week.
The first category is spelling and grammar errors. (You could technically break spelling/grammar into two categories.)
The second category is continuity/consistency errors.
You can catch most spelling/grammar errors with a combination of improving your craft, spell-checkers like Word and Grammarly, and a good editor or (editors). You won’t catch them all, but you’ll get a lot of them, enough for readers not to notice.
Continuity errors are trickier. These are errors such as giving a character blue eyes on page 1 and green eyes on page 10, or writing mental images that don’t make sense in the reader’s head. These are impossible to catch programmatically, and the only way you can root them out is to find the right editor.
I find that a good continuity editor has a particularly nitpicky personality. For me personally, I’ve only had 2 editors in the dozen or so I’ve used who fit this bill. It’s a particular skillset that you have to learn to look for.
WHY DO WE CARE ABOUT THIS?
You can catch more spelling and grammar errors than you think if you take a creative approach.
What if, after your editor sent your edits back, if you could create a system that “scored” or “graded” each chapter you wrote based on how many edits you received and the types of edits your editor made? (Remember the goal: to catch as many errors as possible to put into your engine so that your editor won’t have to catch them next time).
A scoring model might include:
- The number of edits made by your editor as tracked changes (these tend to be spelling/grammar)
- The number of comments made by your editor (these tend to be continuity edits)
- Your mood when you wrote the chapter (what if it were true that you wrote worse when you felt worse?)
- Your writing method (perhaps you write better when you’re at your laptop, but worse when dictating)
The system would take all of these factors into consideration and give you a score for each of your chapters. You would then know, in retrospect, what parts of the book were strongest and weakest from a (strictly copyediting) editorial perspective. Then, you could rank all of your chapter scores from worst to best.
Then, you could look for drivers behind the lowest scoring chapters.
Best of all, you could technically make a scoring engine like this predictive. In other words, you can use this as a way to help you identify potential problem chapters based on how they profile in certain parts of your scoring engine. So you could potentially know upfront which chapters your editor is going to spend the most time on.
OOOOH, WHAT DOES THIS LOOK LIKE?
I spent about an hour this evening hashing out what this might look like:
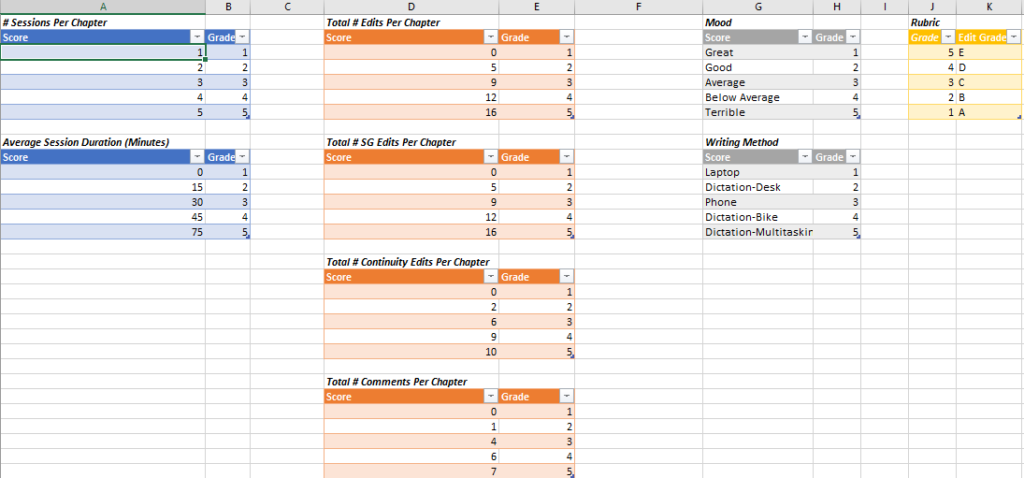
This isn’t perfect, but these are the criteria that I want to measure my novel against. The lower the “score” on these charts, the better.
I have some theories:
- Words I write on my laptop tend to be cleaner than words I write on my phone, for example.
- I write better when I feel great.
- And so on.
Then, I created a scoring log for the novel. There’s actually a lot more on this spreadsheet but I hid some of the items:

(SG stands for Spelling and Grammar, and the “comments” tracks continuity errors.)
I have a neat little add-in in Word that counts the number of edits I receive, so I used that to figure out what my edit counts were. This did not take long at all.
The data on this sheet isn’t my current novel, but it was a test. Since the novel hasn’t gone to my editor yet, I instead used the first five chapters of Shadow Deal, a recent novel I wrote. So bear with me on the analysis because it’s merely just a demo of what I can do with this, and a taste of what the REAL book might look like.
- The lower the score, the better.
- If you look at Chapter 4, it scored the worst. Why? It had a lot of spelling/grammar errors AND continuity errors. Why? Well, it was a fast-paced scene. So a potential driver here might be that when I write fast-paced scenes, I tend to create more errors. Therefore, I might want to check my other fast-paced scenes to see if I see the same thing. It might also be a good idea to “flag” fast-paced scenes for my editor so she knows to spend some more time in these scenes moving forward. The power of insights!
- I dug deeper into the “type” of spelling and grammar errors I made in Chapter 4. Turns out that 30% of them were a really quirky error that I make a lot…sometimes I repeat the same word in a paragraph or within a few paragraphs, to the point where it looks and sounds weird and repetitive. For example, I might accidentally use the word “scream” four times on the same page. For some reason I can’t see it when I do it but my editor almost always catches it. Can I find a way to solve this problem moving forward and take this off her plate? I think I can, but that’s a topic for another time. But basically, if I could have eliminated these errors, the chapter would have been 30% cleaner and it would have scored considerably better, somewhere in the 2 category, which is akin to a B.
Check out what I mean about the “duplicate” word problem…I definitely need to find a way to solve this. This happened too many times throughout the first few chapters, albeit with different words.

Anyway, if this data were true, then it would have taught me something very important from tonight’s analysis that I can share with my editor this weekend—let’s pay closer attention to fast-paced scenes. (That might actually be true, but I am not making any assumptions at this point.)
It also taught me that I HAVE to solve the duplicate word problem. It's a problem that doesn't just affect readers–it also presents poorly in audio. Fortunately my editor caught these, but it's on me to address it further.
When you can find the trends, you can share a summary of them with your editor so they can customize their approach with your manuscripts future-forward.
There's so much to explore here, and it's somewhat doable to create a system that can do this. I'm in the process of building part of it.
OKAY, I’M DONE NOW
This is what happens when you have too much time on your hands, guys. LOL
But in all seriousness, this is a pretty important project for a few reasons:
- It will save editing costs over time
- It will free up my editor to focus on more important issues vs. correcting the same mistakes over and over again
- It helps me create cleaner manuscripts for my readers, which moves me toward my goal of becoming a world class content creator
- It improves my craft using errors that I am actually prone to making instead of generic English rules.
Anyhoo, did this make sense? What could I have explained better? I’m always looking to make sure that I explain my projects clearly. Otherwise it’s not valuable for y’all.
Have a good night.
